Fast and accurate models in computer-vision are critical for optimizing costs in cloud services and enabling compute on edge-devices. Often papers & libraries report GFLOPs & model size as a proxy metric for speed, but is that reliable?
To put this to the test, we have benchmarked common computer-vision models on a Nvidia 3090 using TensorRT-10.0.1
The key findings are,
✅ Compute time is independent of model size and GFLOPs.
✅ The fastest model on a small image doesn’t guarantee its the fastest on a large image
✅ Pick Mobilenet_v3_small for FP32 precision
✅ Pick ResNet-18 or Fast-SCNN for FP16 & INT8 precision
✅ FP16 is 35~300% faster than FP32 (more consistent speed-ups at higher resolutions / batch-sizes)
✅ INT8 is 200~700% faster than FP32 (its highly dependent on your models architecture)
Methodology
The benchmark was performed with ML Benchmark which is built on trtexec. The following trtexec flags were used,
--cudaGraphs- Further speed-up by removing CPU overhead in kernel launches--noDataTransfer- Disabling D2H & H2D transfers, reducing variation caused by the CPU.--useSpinLock- Spin-locking in benchmarking to avoid timing noise being caused by the OS.--avgRuns=50- Recording time over more runs to reduce variation (default=10)
The timing data was saved directly from trteexec with --exportTimes.
Models
In addition to Resnet & VGG the following models were benchmarked:
Several models reporting to be faster & more accurate than Fast-SCNN were not benchmarked (DAPSPNet , DDRNet23_slim , and FasterSeg).
Results
The graphs below plot FPS against resolution for models. All curves are non-linear, making it difficult to predict model compute time without benchmarking. Most of the backbones we are testing have similar compute time.
| Nvidia 3090 w/ FP16 | Nvidia 3090 w/ FP16 & INT8 |
|---|---|
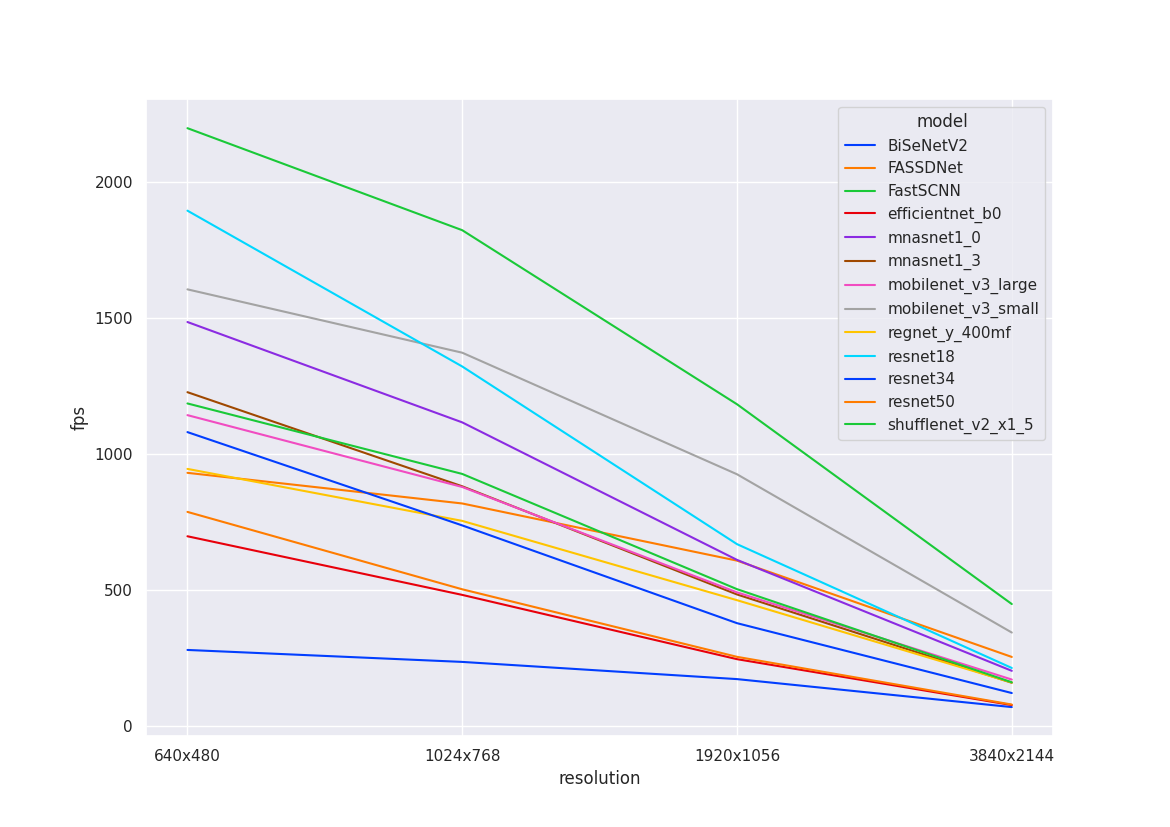 |
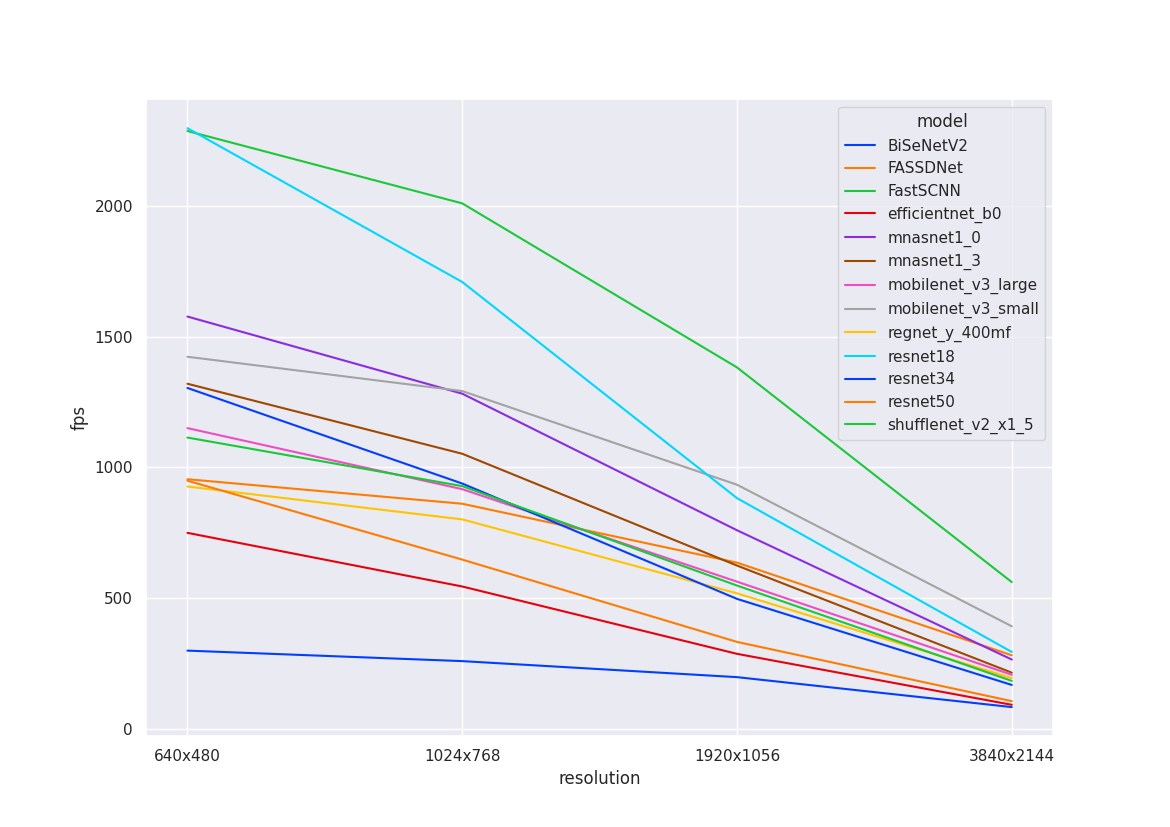 |
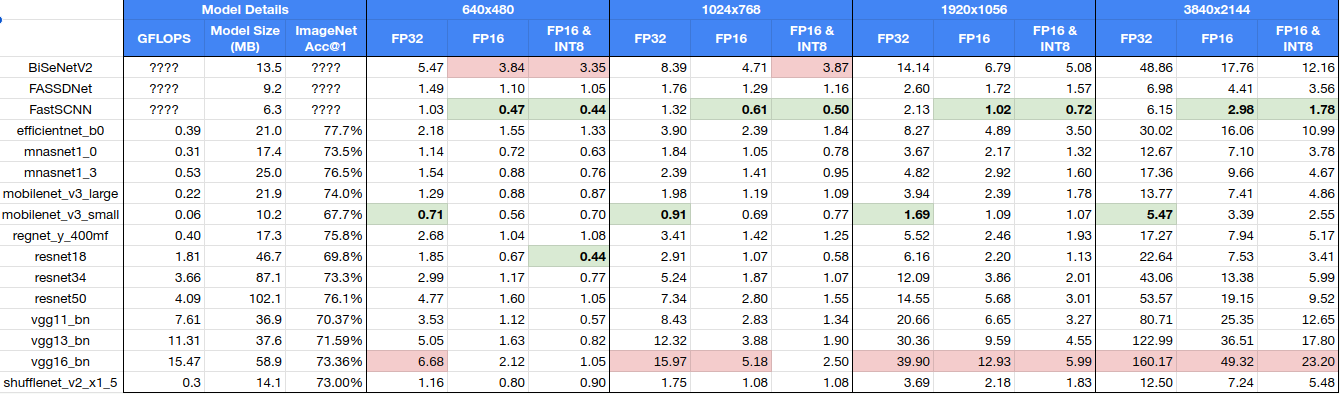
Below is the table of raw results, showing the number of milliseconds for a single inference with each model. It includes additional information on the accuracy, GFLOPs, and model size. We can see that the compute time is not correlated with the GFLOPs & model-size.